- Индексация: Секреты Молниеносной Работы с Локальными Базами Данных
- Что такое Индексация и Зачем Она Нужна?
- Типы Индексов
- B-Tree Индексы
- Hash Индексы
- Full-Text Индексы
- Spatial Индексы
- Как Правильно Индексировать Данные?
- Определение Столбцов для Индексации
- Комбинированные Индексы
- Избегайте Избыточной Индексации
- Практические Советы по Оптимизации Индексации
- Примеры Индексации в Разных СУБД
- SQLite
- MySQL
- PostgreSQL
- Когда Индексация Может Быть Вредной?
- Мониторинг и Обслуживание Индексов
Индексация: Секреты Молниеносной Работы с Локальными Базами Данных
Приветствую вас‚ друзья! Сегодня мы погрузимся в мир локальных баз данных и поговорим о том‚ как сделать их работу не просто быстрой‚ а молниеносной. Мы‚ как и многие из вас‚ сталкивались с ситуациями‚ когда простая операция поиска данных превращается в мучительно долгое ожидание. И решение этой проблемы – в правильной индексации. Готовы узнать все секреты?
Что такое Индексация и Зачем Она Нужна?
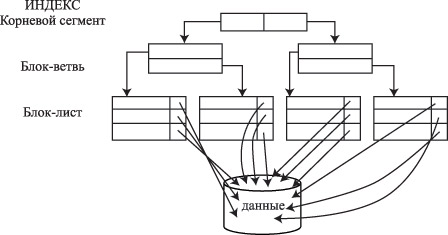
Представьте себе огромную библиотеку‚ где книги расставлены хаотично. Чтобы найти нужную‚ вам придется пересмотреть каждую полку‚ каждую книгу. Индексация в базах данных работает как каталог в библиотеке. Она создает структуру‚ которая позволяет быстро находить нужные записи‚ не перебирая всю таблицу. Без индексации‚ база данных вынуждена выполнять так называемый «полный просмотр таблицы» (table scan)‚ что крайне неэффективно‚ особенно для больших объемов данных.
Индексы – это специальные структуры данных‚ которые содержат копии значений из одного или нескольких столбцов таблицы‚ а также указатели на соответствующие строки в таблице. Эти структуры организованы таким образом‚ чтобы обеспечить быстрый поиск значений. Мы часто используем индексы‚ даже не задумываясь об этом‚ например‚ при поиске информации в интернете.
Типы Индексов
Существует несколько типов индексов‚ каждый из которых имеет свои особенности и подходит для разных сценариев. Давайте рассмотрим основные:
B-Tree Индексы
B-Tree (Balanced Tree) – это самый распространенный тип индекса. Он хорошо подходит для большинства задач‚ включая поиск по диапазону‚ точное соответствие и сортировку. B-Tree индексы поддерживают операции =‚ >‚ <‚ >=‚ <= и BETWEEN. Это наш основной инструмент в борьбе за производительность.
Hash Индексы
Hash индексы используют хеш-функции для вычисления хеш-кода для каждого значения столбца. Они идеально подходят для поиска точного соответствия (=)‚ но не поддерживают поиск по диапазону или сортировку. Hash индексы обычно быстрее‚ чем B-Tree индексы для операций точного соответствия‚ но их применимость ограничена.
Full-Text Индексы
Full-Text индексы предназначены для поиска текста в текстовых столбцах. Они позволяют выполнять сложные поисковые запросы‚ такие как поиск по ключевым словам‚ фразам и морфологическим формам слов. Мы часто используем их для индексации больших текстовых документов.
Spatial Индексы
Spatial индексы используются для индексации географических данных‚ таких как координаты‚ линии и полигоны. Они позволяют выполнять быстрые запросы‚ связанные с пространственным расположением объектов‚ например‚ поиск ближайших объектов или объектов‚ находящихся в определенной области.
Как Правильно Индексировать Данные?
Индексация – это не просто добавление индексов ко всем столбцам. Неправильная индексация может привести к снижению производительности‚ увеличению объема занимаемого дискового пространства и замедлению операций записи. Важно понимать‚ какие столбцы нуждаются в индексации и какие типы индексов лучше всего подходят для конкретных задач.
Определение Столбцов для Индексации
В первую очередь‚ необходимо определить‚ какие столбцы наиболее часто используются в запросах WHERE‚ JOIN и ORDER BY. Эти столбцы являются основными кандидатами на индексацию. Также стоит учитывать кардинальность столбца – количество уникальных значений. Столбцы с низкой кардинальностью (например‚ пол‚ статус) обычно неэффективно индексировать.
Комбинированные Индексы
Комбинированные индексы (composite indexes) – это индексы‚ которые охватывают несколько столбцов. Они особенно полезны‚ когда запросы часто используют несколько столбцов в условиях WHERE. Порядок столбцов в комбинированном индексе имеет значение. Столбцы‚ которые наиболее часто используются в запросах‚ должны идти первыми.
Рассмотрим пример. Если у нас есть таблица users с столбцами first_name‚ last_name и email‚ и мы часто выполняем запросы вида WHERE first_name = 'John' AND last_name = 'Doe'‚ то имеет смысл создать комбинированный индекс по столбцам (first_name‚ last_name).
Избегайте Избыточной Индексации
Слишком большое количество индексов может замедлить операции записи (INSERT‚ UPDATE‚ DELETE)‚ так как при каждой записи необходимо обновлять все индексы. Поэтому важно тщательно анализировать необходимость каждого индекса и удалять неиспользуемые индексы.
"Преждевременная оптимизация ⏤ корень всех зол." ౼ Дональд Кнут
Практические Советы по Оптимизации Индексации
Теперь‚ когда мы разобрались с теорией‚ давайте перейдем к практическим советам‚ которые помогут нам оптимизировать индексацию локальных баз данных:
- Используйте инструменты профилирования запросов: Многие СУБД предоставляют инструменты для анализа производительности запросов. Используйте их‚ чтобы выявить проблемные запросы и определить‚ какие индексы могут улучшить их производительность.
- Регулярно проверяйте индексы на фрагментацию: Фрагментация индексов может снизить производительность. Регулярно перестраивайте индексы‚ чтобы уменьшить фрагментацию.
- Обновляйте статистику индексов: СУБД использует статистику индексов для оптимизации запросов. Регулярно обновляйте статистику‚ чтобы обеспечить оптимальный выбор планов выполнения запросов.
- Тестируйте изменения: Перед внесением изменений в индексацию на рабочей базе данных‚ протестируйте их на тестовой базе данных с аналогичным объемом данных.
Примеры Индексации в Разных СУБД
Синтаксис создания индексов может немного отличаться в разных СУБД. Давайте рассмотрим примеры для популярных локальных баз данных:
SQLite
В SQLite создание индекса выглядит следующим образом:
CREATE INDEX idx_users_last_name ON users (last_name);Для создания комбинированного индекса:
CREATE INDEX idx_users_first_name_last_name ON users (first_name‚ last_name);MySQL
В MySQL создание индекса:
CREATE INDEX idx_users_last_name ON users (last_name);Комбинированный индекс:
CREATE INDEX idx_users_first_name_last_name ON users (first_name‚ last_name);PostgreSQL
В PostgreSQL создание индекса:
CREATE INDEX idx_users_last_name ON users (last_name);Комбинированный индекс:
CREATE INDEX idx_users_first_name_last_name ON users (first_name‚ last_name);Когда Индексация Может Быть Вредной?
Как мы уже говорили‚ избыточная индексация может негативно сказаться на производительности. Вот несколько ситуаций‚ когда стоит задуматся об удалении или пересмотре индексов:
- Редко используемые индексы: Если индекс не используется в запросах‚ он только занимает место и замедляет операции записи.
- Индексы на столбцах с низкой кардинальностью: Индексы на столбцах с небольшим количеством уникальных значений (например‚ пол‚ статус) обычно неэффективны.
- Индексы‚ перекрывающиеся с комбинированными индексами: Если у вас есть комбинированный индекс
(A‚ B)‚ то отдельный индекс на столбцеAможет быть избыточным.
Мониторинг и Обслуживание Индексов
Индексация – это не разовая задача‚ а непрерывный процесс. Необходимо регулярно мониторить производительность запросов‚ анализировать использование индексов и перестраивать или удалять неэффективные индексы. Многие СУБД предоставляют инструменты для мониторинга и обслуживания индексов‚ такие как статистики использования индексов‚ рекомендации по оптимизации и инструменты перестройки индексов.
Оптимизация работы с локальными базами данных – это искусство‚ требующее знаний‚ опыта и постоянного внимания. Индексация – один из ключевых инструментов в этом искусстве. Правильно настроенные индексы могут значительно ускорить выполнение запросов и повысить общую производительность базы данных. Но помните‚ что индексация – это не панацея‚ и важно тщательно анализировать необходимость каждого индекса и регулярно мониторить их эффективность. Надеемся‚ что наши советы помогут вам в этом нелегком‚ но увлекательном деле! Мы верим в вас!
Подробнее
| Оптимизация баз данных | Индексация SQL | Ускорение запросов | Типы индексов | Создание индексов |
|---|---|---|---|---|
| Комбинированные индексы | Производительность БД | Мониторинг индексов | SQLite индексация | MySQL индексация |